
深度解析各种网站页面跳转方法原理流程及优劣势剖析比照

什么是页面跳转,为什么页面跳转,怎样进行页面跳转。关于网页跳转技能许多,文章也许多,办法代码都许多,可是这些办法不同在那里,那些办法速度快,那些办法灵敏,那些办法用户能感觉到,为什么能感觉到。我看了一些文章,结合多年的作业经验,经过制作序列图等办法简略总结一下,换个视点了解一下,期望对咱们有所协助! 本文要点在于比较http跳转,html跳转,js跳转的作业流程,以及要点剖析他们在时刻开支上的状况,一起咱们要点在于制作一些图形,然后期望读者能够从图中领会到差异,需求读者领会的当地都用特别区域标识出来了。请咱们留意。 一.什么是页面跳转 网站都是由各式各样页面组成,正常状况下A页面里边包含B页面,C页面的链接,用户在阅读A页面进程中,手艺人为点击B链接,然后用户阅读器就显现到B页面。这个进程咱们就能够叫页面跳转。 咱们明显不是说这种页面跳转。咱们考虑如下场景,一个网站由A,B,C页面构成。正常他们有他们自己显现内容。跟着时刻推移,发现A页面内容应该同C页面内容相同,可是因为A页面现已被许多用户收藏在阅读器的收藏夹中,或许被查找引擎录入,若是现在撤销A页面的地址(便是撤销页面),则对用户是个十分糟糕的作业,可是一起保护两个页面A及C又是个费事的作业,稍有忽略就会形成内容不一致,给用户形成困惑,一起查找引擎也会不认可。 怎么确保A地址不撤销,一起又精确确保两个页面显现内容相一致? 咱们今日要处理的是在没有用户干涉下的页面跳转,完结当用户需求显现页面A时,咱们给他显现页面C的内容。 别的为了阐明问题便利,咱们一起也假定页面B内容也指向内容C,只是选用跳转技能不一样,这样咱们便利差异两种行为的不同。
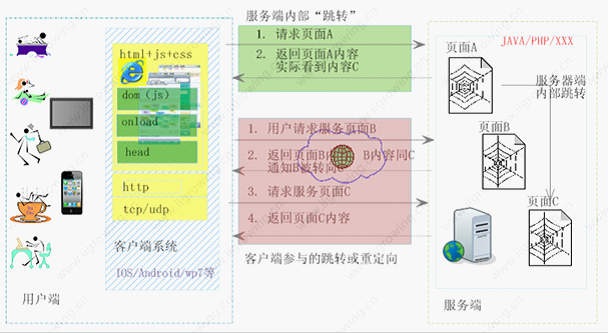
图1 阅读器拜访服务器示意图
如上图中,展现了用户拜访服务器获取页面的一个根本进程。图中首要分为两个部分,左边区域是用户端, 右侧区域是服务端,用户端的用户经过手机或许电脑或许智能设备拜访服务端页面。 服务端由若干页面构成,这儿简化了服务端行为,而且笼统成三个页面A,B,C,正常状况下服务端应该有许多Action方针,Action方针同页面相对应,供给各种服务,咱们只是简化Page:A, Page:B, Page:C 用户端便是手机, 包含手机操作操作体系, 网络层(tcp/ip/udp等),http等协议层,以及阅读器,阅读器内部进行html的解析,css烘托,js履行引擎等等。 典型用户页面阅读行为如下: 1. 用户发动阅读器 2. 在阅读器地址中输入url地址 3. 阅读器建议http恳求 4. 网络层建议tcp恳求到服务器,传输http数据包 5. 服务器接纳到恳求后进行处理,然后回来相关页面内容 6. Tcp接纳回来数据给http协议解析体系 7. http将回来数据回来阅读器 8. 阅读器解析html数据,处理html head 9. 依据head处理后续作业 10. 解析body数据 11. 处理装载作业Onload(现已开端js的履行,在装入数据进程中现已能够履行一些js作业,详细要依据页面以及阅读器特性而定) 12. 依据css进行显现,履行js 13. 用户进行后续作业 以上只是是典型阅读器行为, 详细阅读器行为同页面内容、阅读器特性等都有联络,要详细剖析。 二.页面跳转的分类 依据上面的图1,咱们能够有如下分类办法: 一)以跳转地址发作体系那一侧分为:
服务端跳转 页面跳转发作在服务端,服务端担任将实践内容获取,然后发送给客户端,这个状况下,一般用户不会感觉到跳转的实践行为,因而有些时分咱们也不叫做跳转。详细的服务端跳转行为有许多,各个技能都有各自的特色,例如: Struts2依据注解服务端跳转、<request.getRequestDispatcher(“xx.jsp”).forward(request,response)、<jsp:forward page=””/ >等,php也有自己的放回,总归各自有各自的办法,咱们自己去查找吧。 客户端跳转 跳转行为需求客户单程序参加的一种行为(天然不是用户参加的,那个不是本文评论的)。在这个进程中,一般用户必定会知道的,阅读器地址栏会发作改变,这个分类比较多,咱们专门进行一个分类。 二)用户端跳转中,咱们依据跳转行为发作在那个软件层次,分为:http层跳转、运用层跳转;运用层跳转持续分为:html head跳转、js跳转等。 http层跳转 http跳转是指server依据作业状况经过http回来状况码,指示客户端阅读器跳转到相应页面的进程,一般回来码是302.,下面是http302状况码的界说: Html head头指令跳转 在html代码的head中增加特别标签,如下 <meta http-equiv=”refresh” content=”5; url=https://www.youhua.net.cn/” /> 表明:5秒之后转到我国搜索引擎优化优化网网站主页。 这个跳转需求阅读器详细解析html后采能进行,稳重更多时刻才干进行,或许状况更杂乱。 Js跳转 经过在html代码中增加js代码,经过js代码完结跳转 <script language=”javascript” type=”text/javascript”> window.location.href=”login.jsp?backurl=”+window.location.href; </script> 这个跳转应该比html head跳转更向后推迟。 三.服务端跳转流程 页面跳转显现的内容发作在服务端,服务端担任将实践内容获取到,然后发送给客户端。一般用户不会感觉到跳转的实践行为,因而有些时分咱们也不叫做跳转 详细作业的参阅进程如下:
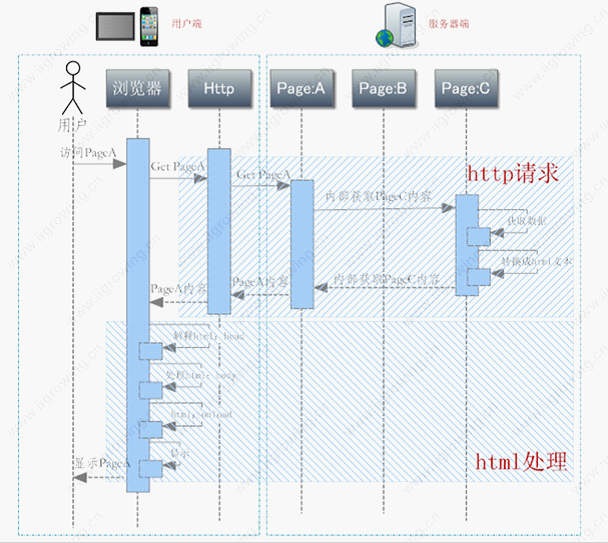
如上图,用户恳求拜访PageA,页面A内容指向页面C,相关进程如下: 1. 用户经过阅读器拜访PageA 2. 阅读器经过http处理模块恳求 Get PageA 3. http处理模块同服务器树立tcp衔接,并宣布恳求获取PageA指令 4. PageA内容指向PageC,经过内部程序将内容C获取到本地 5. PageA接纳到PageC的数据后,将数据回来给http模块 6. http模块接纳到数据后回来给阅读器 7. 阅读器接纳到http回来的html数据后,解析html的head 8. 处理html的body 9. 处理html的onload办法 10. 阅读器最终将数据等显现给用户 留意:图中不同斜线的区域 经过server跳转后,用户看到的是PageC的内容,可是阅读器地址栏中地址是PageA的地址。 长处:跳转行为在server进行, 一次tcp衔接完结相关操作,对用户是通明的,不会形成疑问。 缺陷:对用户躲藏了信息,跳转行为都发作在server端,对server有压力。 server端功用各异,需求分工担任,当用户拜访某功用后,需求回来别的一个功用,这个时分没必要把悉数功用都放到一个服务器上。 例如: 单点登录:用户在某个服务器上登录成功后,必定要在从头跳转到功用服务器上。 网络付出:用户在银行的网站付出完结后,有必要从头定向到别的企业运用服务器上。 适用范围:运用内部体系,恰当的包含联络时。 四.http跳转流程 http跳转是指server依据作业状况经过http回来状况码,指示客户端阅读器跳转到相应页面的进程,一般回来码是302.,下面是http302跳转的相关参阅流程 留意图中,区域,色彩,斜线等等。
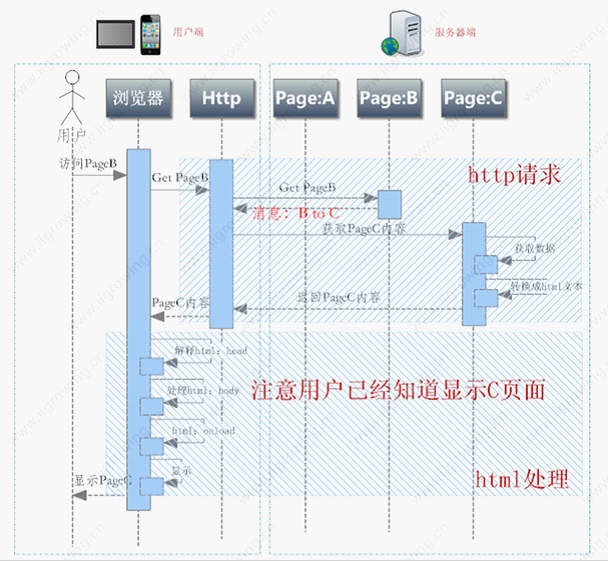
如上图,用户恳求拜访PageB,页面B内容指向页面C,相关进程如下: 1. 用户经过阅读器拜访PageB 2. 阅读器经过http处理模块恳求 Get PageB 3. http处理模块同服务器树立tcp衔接,并宣布恳求获取PageB 4. PageB内容指向PageC,PageB的处理模块经过http的重定向协议告诉客户端程序,经过发送音讯,302,以及跳到意图地址等进行 5. http处理模块接纳到音讯后直接跳转到方针地址,一起告诉阅读器(修正地址栏) 6. http处理模块恳求PageC页面内容 7. PageC处理模块处理数据,生成html代码,回来数据给http处理模块 8. http处理模块接纳到数据后放回数据给阅读器 9. 阅读器接纳到http回来的html数据后,解析html的head 10. 处理html的body 11. 处理html的onload办法 12. 阅读器最终将数据等显现给用户 长处:相应速度快,在http1.1协议下经过适合的设置能够运用同一个tcp衔接,节约网络时刻,服务器及用户端都不需求进行额定的数据处理作业,节约时刻。 缺陷:只是能做跳转没有其他功用,依据js及html的跳转能够挑选延时跳转,可是302无法挑选延时跳转等 适用范围:快速跳转,不需求延时,常常用在两个体系之间跳转等。 五.Html refresh跳转流程 经过在html head中增加<meta>标签,在标签里指定相关参数,指示阅读器跳转到相应页面,相关跳转有必要在http层面将html数据传输给阅读器后,阅读器解说html代码进程中,发现跳转而且依据跳转指令跳转到相应页面。 参阅流程如下图:
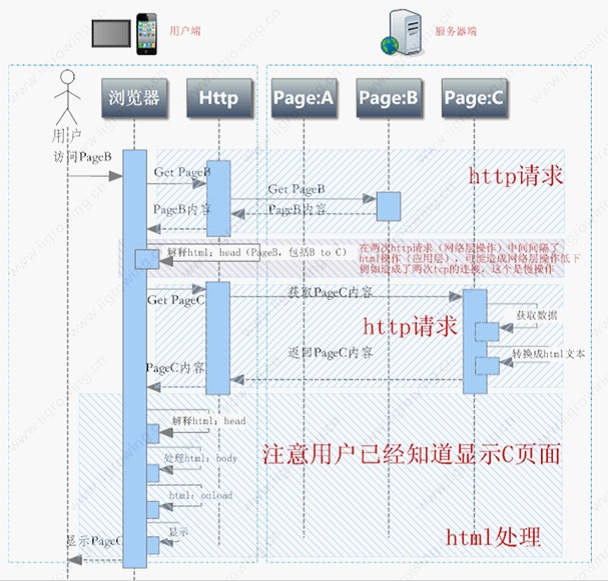
如上图,用户恳求拜访PageB,页面B内容指向页面C,相关进程如下: 1. 用户经过阅读器拜访PageB 2. 阅读器经过http处理模块恳求 Get PageB 3. http处理模块同服务器树立tcp衔接并宣布恳求获取PageB 4. PageB处理模块处理数据,生成html代码,最终将html经过http协议传输回去。 5. http后将数据放回给阅读器,阅读器开端处理html 6. 阅读器首要会处理html的head部分,最终发现有跳转的相关指令 7. 阅读器依据跳转指令,从头联络http模块,宣布获取PageC的指令 8. http经过tcp衔接到服务器,获取PageC内容,然后回来给阅读器 9. 阅读器接纳到http回来的html数据后从头处理html,首要解析html的head 10. 处理html的body 11. 处理html的onload办法 12. 阅读器最终将数据等显现给用户 长处:跳转办法灵敏,能够指定延时跳转等等 缺陷:或许屡次树立tcp衔接,在低速网络下功率更低,糟蹋客户端的时刻 六.Html js 完结跳转作业流程 最终来看一下js跳转,作业中每个阅读器都有自己的js履行引擎,履行引擎依据js代码,来动态调用阅读器进行跳转,相关参阅代码如下: <script language=”javascript” type=”text/javascript”> window.location.href=”login.jsp?backurl=”+window.location.href; </script> 详细js跳转进程如下图

1. 用户经过阅读器拜访PageB 2. 阅读器经过http处理模块恳求 Get PageB 3. http处理模块同服务器树立tcp衔接同server树立衔接,并宣布恳求获取PageB 4. PageB处理模块处理数据,生成html代码,最终将html经过http协议传输回去。 5. http后将数据放回给阅读器,阅读器开端处理html 6. 阅读器首要会处理html的head部分,最终会发现有跳转的相关指令 7. 阅读器处理html的body,以及js等,最终依据js的指令指示阅读器获取页面C 8. 最终依据js的指令指示阅读器获取页面C阅读器会依据跳转指令,从头联络http模块,宣布获取PageC的指令 9. http经过tcp衔接到服务器,最终获取PageC的内容,然后回来给阅读器 10. 阅读器接纳到http回来的html数据后从头处理html,首要解析html的head 11. 处理html的body 12. 处理html的onload办法 13. 阅读器最终将数据等显现给用户 长处:跳转办法灵敏,能够指定延时跳转等等, 缺陷:或许屡次树立tcp衔接,在低速网络下功率更低,糟蹋客户端的时刻 运用拜访:快速跳转,不需求延时,常常用在两个体系之间跳转等。 七.小结 每种跳转办法关于用户来讲都带来了内容上的改变,原以为A页面的内容变成C页面内容。 跳转的办法有许多,无法一一列举,当咱们适用时怎么挑选那种类别时,需求弄理解每一种跳转的特色,包含:功用,功用等 依据不同网络状况进行不同的挑选,例如有的网络树立tcp衔接速度慢,这个时分就适合挑选server端的跳转等 若是确保体系之间的耦合联络更小,体系之间更灵敏则需求选用http办法跳转、js跳转,html跳转等。 有的时分需求在跳转前进行一些判别或许额定的操作等,便是js跳转比较便利,可是也有个阅读器适配的问题。有时分一个js兼容性欠好的js代码或许不作业,形成部分用户无法跳转。 八.页面跳转最糟糕的状况 当A跳转到B时,咱们用符号A–>B表明,下面的循环跳转A–>B–>C–>A ,会发作什么作业。 若是循环跳转只是发作在server端,则相关体系会敏捷被拖垮。 若是循环跳转发作在客户端参加的体系中,很快客户端及server端都会发作问题。 因而循环跳转咱们是要严厉防止的,处理办法: 1. 不跳转,可是不或许完全防止,而且不太或许完结,一般体系都是敞开的体系,会不断增加功用,即便当时没有跳转,可是过几个月。。。。。。 2. 打破跳转的循环,加强体系的查看力度防止循环跳转的发作。 3. 最重要的,监控体系,当发现某个客户端或许体系在单位时刻内有过多的拜访时,自动断开衔接或许回绝这个客户端的拜访等等。这个十分重要,一个好的体系是有必要有这个功用的,不然即便没有循环跳转,可是若是用户接连快速拜访一个页面也是有很大问题的,例如ie中按下F5键 循环改写页面,若是没有检测机制。。。。 更多黑帽SEO技能请重视我国搜索引擎优化优化网(www.youhua.net.cn),一个专心黑帽SEO优化排名技能研究与学习教程共享的网站! 本文由我国搜索引擎优化优化网聚合网络收拾发布,转载请注明来历,谢谢!
本文链接:https://www.youhua.net.cn/jishu/71.html
